This guide shows you how to use CC-Jupyter-Service to execute jupyter notebooks. It will show you how to use external data in you notebook and how to specify Hardware and Software requirements.
It is written for students or employees of the HTW Berlin.
CC-Jupyter-Service enables you to execute jupyter notebooks. Therefor it is required to write and save a jupyter notebook on your machine (or at least you need access to a notebook file).
CC-Jupyter-Service uses CC-Agency for authorization and execution of the notebooks. Therefor it is required to have access to a CC-Agency installation. You will need the URL of the agency and a valid Username and Password combination.
You can test whether you have access to an agency by accessing "agencyUrl/nodes" with your browser (For HTW members you could try https://agency.f4.htw-berlin.de/dt/nodes via VPN).
You will be asked for username/password.
If you cannot access the agency it may be required to access it via VPN (See this guide on how to setup VPN at the HTW Berlin).
To use an cc-jupyter-service you need to access its webpage. The HTW hosts a CC-Jupyter-Service installation here. You probably need to access it via VPN.
CC-Jupyter-Service executes your notebooks using docker. If you have special software requirements, you may need to build your own docker image.
If you want to use external data in your jupyter notebook you need SSH access on a SSH server, that is accessible inside the HTW Network.
Via VPN you should be able to access it using ssh myusername@ssh-server-name in a terminal.
The login page is the first page you see, when accessing CC-Jupyter-Service with your browser. You can access the HTW installation at https://avocado01.f4.htw-berlin.de/ccjupyterservice.
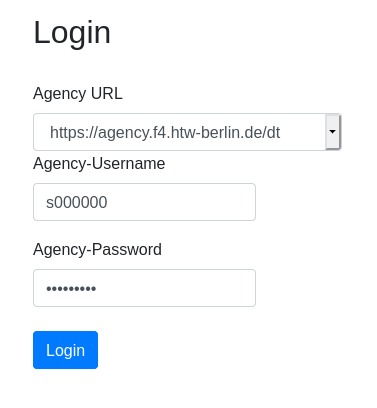
Here you need the agency URL and your username/password combination of your agency account.
If you are a student at the HTW you should probably select https://agency.f4.htw-berlin.de/dt.
If you have logged in successfully you see the execution page.
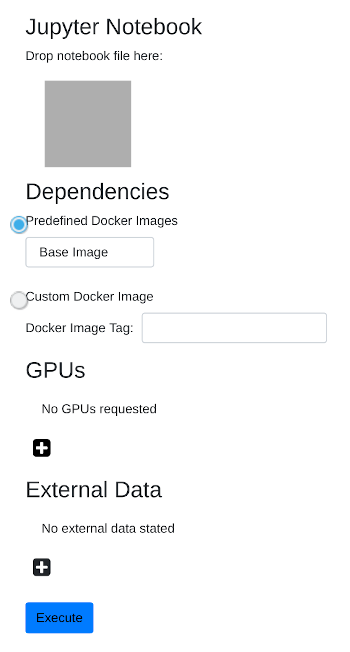
As stated previously CC-Jupyter-Service executes a jupyter notebook. In the first section of the execution page you can drag and drop your jupyter notebook file.
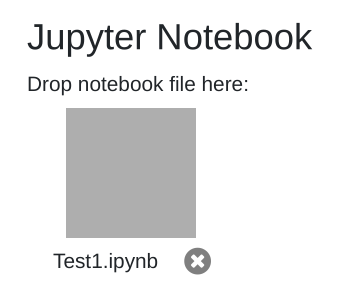
Afterwards you can see the notebook file. To execute a different notebook remove the notebook by clicking the X-Button next to the notebook name.
CC-Jupyter-Service executes your notebook inside a docker container. If you don't need extra software you can simply select "Base Image". There is also a predefined "Tensorflow Image" and a "Pytorch Image".
There are two options in case you want to use software that is not installed in the predefined images.
Option 1: The first approach is easier but slower and less flexible. CC-Jupyter-Service allows you to specify a requirements.txt file that will be installed before the execution of your notebook. The downside is that the python packages are installed every time you execute the notebook, which slows down the execution. Also this does not work, if you want to install software not available through pip.
You can use pip freeze > requirements.txt to create a requirements.txt file that lists all your local installed packages or write the requirements.txt by hand.
For example:
tqdm==4.42.1
paramiko==2.7.1
Option 2: The faster but more complex way is to build your own docker image. Afterwards you can choose this image by selecting "Custom Docker Image" and specifying your image tag. This method is very flexible as any software can be installed, but there are some requirements to make your docker image work under CC-Jupyter-Service. Read this for more information on how to build your own docker image for CC-Jupyter-Service.
For machine learning applications or image processing it is sometimes useful to use GPU-acceleration. For this purpose you can require one or more GPUs by clicking on the Plus-Button under GPUs. A new GPU-Entry should appear where you can select the amount of VRAM of this GPU. You can require as much GPUs as you like but if the cluster does not have the possibility to fullfill these requirements the execution of the notebook will fail.
When using dt-agency you can select only one GPU, otherwise the execution will fail.
This section is a little bit more challenging, so we will work through an example.
We can use this functionality if we want to use files or directories which are not present in the docker image or if you want to upload files or directories after the execution of the notebook.
For this to work we need an ssh-storage-server that is reachable for the execution cluster (for dt-agency you could use the dt1.f4.htw-berlin.de storage server) that we can access via SSH.
We should login to this SSH-Server via SSH and create the data we want to access in your notebook.
In this example we will create a directory test_directory containing the files test_file1.txt and test_file2.txt.
ssh [email protected]
# inside ssh
echo $HOME # for example gives: /home/s0000000
mkdir test_directory
echo "content1" > test_directory/test_file1.txt
echo "content2" > test_directory/test_file2.txtBefore editing the external data section in the CC-Jupyter-Service UI, we should prepare our notebook to work with the external data. Therefore add a new cell at the top of your notebook.
my_input_directory = NoneMake sure to add the parameters tag to the cell as described here.
This cell defines the input files and directories of our notebook.
Instead of None we can also use other values.
These values are overwritten by CC-Jupyter-Service and then contain the path to the file or directory that we want to specify now in the CC-Jupyter-Service UI.
To specify which files or directories we want to use in our notebook we click at the plus-button in the "External Data" section.
The first thing we enter is name of our variable that we specified in our parameters cell (in this example my_input_directory).
Then we have to choose between File, Directory and some other possible types. As my_input_directory is a directory we choose Directory.
Next we choose the way how to transfer the files or directories to our notebook. Currently there is only one option SSH.
Now there are some more fields to fill. The Host specifies the ssh-storage-server that we want to access.
So we fill in the hostname of the storage server, in our example dt1.f4.htw-berlin.de.
Next we have to specify the path to the file or directory on our storage server that we want to use.
In our example it would be /home/s0000000/test_directory. We can also use the relative path test_directory, which will be interpreted relative to our home directory.
Do not use ~ or environment variables.
Now the CC-Jupyter-Service knows where to find our data (host and path) and the parameter you want to define with it (in our example my_input_directory).
But to access these files we need authentication information.
So we have to supply our Username and Password combination we used to login into our SSH-Server (Username should be s0000000).
The last thing to specify is whether we want to copy our directory or to mount it. Most of the time mounting is faster and better, so we tick the checkbox.
That's it. Now we can use this directory inside our notebook and list its content for example:
import os
print(os.listdir(my_input_directory))Another advantage of mounting the directory is that we can create new files inside our directory, which will be present on our SSH-Server afterwards. We could for example create a file in our notebook:
import os
new_path = os.path.join(my_input_directory, 'my_new_file.txt')
with open(new_path, 'w') as f:
f.write('This is some new content')If we mount my_input_directory the file my_new_file.txt will be created on our ssh-storage-server, so we can use it after the notebook execution finished.
To run our notebook we click on the Execute-Button. This will start the execution and takes us to the result page.
The result page lists the executed notebooks and some meta information.
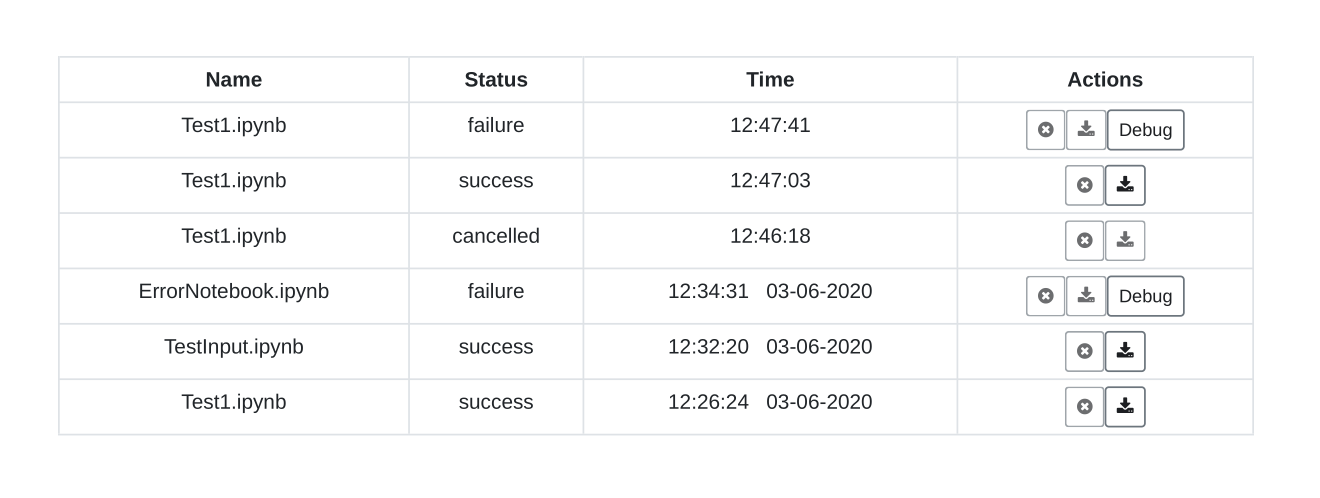
On the left side we can see the filename of our jupyter notebook. Next to it we see the execution status. There are four possible values for this.
Notebooks in state processing are currently processed. The status is refreshed in short time intervals but we can also update their status by clicking on Results tab of the top navigation bar.
If everything worked as expected the notebook will have status success. Then we can click on the download button on the right side and view our executed notebook.
If something went wrong the notebook will be in state failed. Then we can view some debug information hopefully saying something about the error that occurred.
On the right side we can cancel a processing notebook. This will lead to state cancelled.
If you want to execute another notebook we can switch back to the execution page by clicking on "Execution" at the top navigation bar.
Sometimes we need software that is not present in the predefined images. Than we can build our own docker image and execute our notebook using the new image.
We are not going to cover how to build a docker image or what a dockerfile is. If you don't know docker take a look at the Docker-Quickstart and the Dockerfile-Reference.
There are some requirements that our docker image must met so it can be used within CC-Jupyter-Service. To make your image work with CC-Jupyter-Service add the following code snippets to your Dockerfile.
Working Dockerfile examples for the predefined docker images can be found here.
First of all make sure python3 and pip is installed:
RUN apt-get update && apt-get install -y python3 && pip3 install --upgrade pipCC-Jupyter-Service uses papermill to execute our notebook, so we have to install it.
RUN pip3 install ipykernel && python3 -m ipykernel install --user && pip install papermillNext we have to install some programs that manage file transfers for us.
RUN pip3 install red-connector-ssh red-connector-httpThe red-connector-http package is required and your image will not work without it.
The red-connector-ssh is only required, if you want to enable External Data via SSH.
If you want to use the mount option when using ssh you also have to install sshfs:
RUN apt-get install -y sshfsAlso we have to create a user with uid 1000.
RUN useradd -ms /bin/bash cc
USER ccCC-Jupyter-Service executes papermill not directly but calls a wrapper program called papermill_wrapper.py. This wrapper is part of the CC-Jupyter-Service implementation, so we
can access it directly via the CC-Jupyter-Service github repository:
RUN mkdir -p "/home/cc/.local/bin" \
&& curl https://raw.githubusercontent.com/curious-containers/cc-jupyter-service/master/cc_jupyter_service/papermill_wrapper.py > /home/cc/.local/bin/papermill_wrapper.py \
&& chmod u+x /home/cc/.local/bin/papermill_wrapper.pyWe place it at /home/cc/.local/bin/papermill_wrapper.py. Later we will add /home/cc/.local/bin to our $PATH Variable.
Also make sure to give execution permissions (with chmod).
Like stated earlier we have to add /home/cc/.local/bin/ to our $PATH to make the papermill_wrapper.py visible to the system.
Also we define some environment variables to prevent encoding issues.
ENV PATH="/home/cc/.local/bin:${PATH}"
ENV LC_ALL="C.UTF-8"
ENV LANG="C.UTF-8"Our final Dockerfile looks like this:
FROM docker.io/deepprojects/cuda-sshfs:9.0-3.5.1
RUN apt-get update \
&& apt-get install -y python3 \
&& pip3 install --upgrade pip
# install connectors
RUN pip3 install ipykernel && python3 -m ipykernel install --user && pip install papermill
RUN pip3 install red-connector-ssh red-connector-http
# create user
RUN useradd -ms /bin/bash cc
USER cc
# install papermill wrapper
RUN mkdir -p "/home/cc/.local/bin" \
&& curl https://raw.githubusercontent.com/curious-containers/cc-jupyter-service/master/cc_jupyter_service/papermill_wrapper.py > /home/cc/.local/bin/papermill_wrapper.py \
&& chmod u+x /home/cc/.local/bin/papermill_wrapper.py
# set environment
ENV PATH="/home/cc/.local/bin:${PATH}"
ENV LC_ALL="C.UTF-8"
ENV LANG="C.UTF-8"We use the base image docker.io/deepprojects/cuda-sshfs:9.0-3.5.1 here so we dont have to install sshfs ourselves.
Now we can build our image using docker build -t our-image-tag:latest . and push it to docker hub docker push our-image-tag:latest.
If we specify our image tag now by using "Custom Docker Image" in CC-Jupyter-Service now, our notebook will be executed within a container that used our new image.