| created_at | updated_at | slug |
|---|---|---|
2019-10-21 13:42:18 -0700 |
2021-02-16 15:25:16 -0800 |
kubernetes-pod-introduction |
Kubernetes是一个容器编排系统,维护节点集群,负责创建、管理容器,本章介绍k8s的核心POD(容器的容器)和负责管理POD策略性工具(决定如何维护POD的数量和方式)。
POD是K8S中最为核心的概念,而其它对象仅仅是用于管理、暴露POD或被POD使用。
POD是一组并置的容器,代表K8S中的基本模块。
容器的目的,是要在一个容器中仅运行一个进程(启动子进程除外),这是因为如果一个容器内运行多个进程,容器还需要负责进程管理、日志管理等繁复工作,这就是docker期望解决的问题。
docker解决了单个容器对应的多进程问题,那么原本需要相互关联的进程就变成了相互关联的容器关系,这种更加高级的关系就由pod来解决。
docker容器之间是完全相互隔离的,但同一个pod中的所有容器都共享相同的主机名和网络接口,其它还是隔离。由于共享相同的IP地址和端口空间,因此同一个pod中的容器不能绑定到相同的端口,否则会冲突。
k8s集群中所有pod都在同一个共享的网络地址空间中,所以pod之间可以直接通过IP地址进行互访,不需要经过网关,就像局域网一样,因此他们的访问是非常直接简单的。
pod可以被视为独立的机器,且由于它比较轻量,因此我们可以轻易拥有尽可能多的pod。
pod的推荐策略是,除了关系非常紧密的组件或进程放在一个pod外,其它情况最好只一个pod对应一个进程。原因有二
- pod是k8s扩容的基本单位,一个pod对应一个进程更加具有弹性
- 一个pod只能部署在一个节点,分多个pod更加容易在多个节点之间平衡,充分利用节点资源。
一个配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: kubia-manual
spec:
containers:
- image: zou8944/kubia
name: kubia2
ports:
- containerPort: 8080
protoctl: TCP# 创建pod
kubectl create -f kubia-manual.yaml # 甚至都不用指定创建什么,因为配置文件中已经说明了创建对象使用ssh登录到pod正在运行的节点,然后使用docker logs命令获取对应容器的日志
直接使用kubectl logs <pod name>获取pod的日志
在不通过service的情况下与特定的pod通信,通常是调试时需要用到,可以将本地网络端口转发到远端集群中的pod
kubectl port-forward kubia-manual 8888:8080 # 将本机的8888端口转到到目标pod的8080端口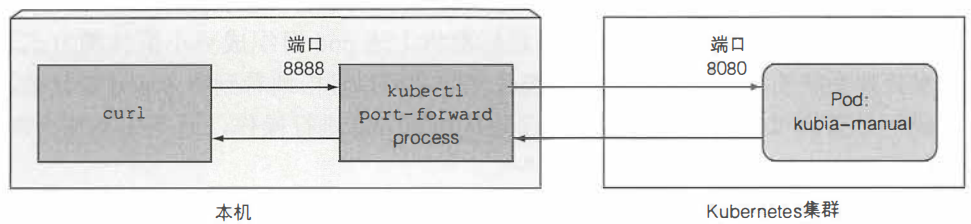
标签是K8S简单且强大的特性,可以应用于任何资源。简单地讲,他就是可以应用于任何资源的键值对。
-
标签可以在创建时pod时指定
...... metadata: name: kubia-manual labels: creatingMethod: manual env: prod ......
-
也可以直接添加或修改标签
# 手动添加一个标签 kubectl label po kubia-manual creation_method=manual # 手动覆盖原有的标签 kubectl label po kubia-manual enb=debug --override
标签结合标签选择器可以带来丰富的效果
# 单个条件
kubectl get po -l creation_method=manual
kubectl get po -l creation_method!=manual
kubectl get po -l env
kubectl get po -l '!env'
kubectl get po -l env in (prod, dev)
kubectl get po -l env notin (prod, dev)
# 多个条件
kubectl get po -l creation_method=manual, env in (prod, dev)让pod随机调度是k8s最为理想的调度,但有时由于硬件或是其它因素导致的需要约束pod调度。
方式是为node添加标签,再在pod创建时利用标签选择器约束其在符合条件的节点上部署
# 将一个节点添加标签 gpu=true
kubectl label node gke-kubia-default-pool-e4a13557-8mqq gpu=true然后在创建时指定选择器
......
spec:
nodeSelector:
gpu: "true"
containers:
......注解同样可以用于所有k8s资源,也是键值对。与标签不同的是它没有注解选择器,但能够容纳更多信息(不超过256KB)。
# 创建注解
kubectl annoteate pod kubia-manual hello="true"
# 查看注解,使用describe命令可以查看注解内容
kubectl describe pod kubia-manual使用标签可以将对象分为多个有重叠的组。但在完全不需要重复的情况下,可以将对象分组到不同的命名空间中。
比如k8s默认将系统相关的node放在kube-system命名空间中,将我们的node放在default命名空间中,这样不会显得混乱,还能防止用户误删除。
和pod一样,命名空间在k8s中液仅仅是一个资源,因此可以通过yaml文件创建
apiVersion: v1
kind: Namespace
metadata:
name: my-first-namespace当然也可以通过命令行直接创建
kubectl create namespace my-first-namespace创建一个资源(不一定是pod哦)时指定命名空间,可以两种方式
-
在metadata字段添加 namespace字段指定命名空间
-
也可以在创建时指定命名空间
kubectl create -f kubia-manual.yaml -n custom-namespace
命名空间并不提供正在运行的对象的任何隔离,仅仅是让我们在管理时候分离开来。当然这也不一定,我们说得是默认情况。
# 按名称删除pod
kubectl delete pod <pod name>
# 使用标签选择器删除pod
kubectl delete po -l creation_method=manual
# 通过删除整个命名空间来删除pod
kubectl delete ns custom-namespace
# 删除命名空间的所有pod,但保留命名空间
kubectl delete po --all我们如果直接删除pod,会发现马上又会重新启动一个pod。这是replicationController在作怪,因为他会保证一致有一个pod在运行。因此要彻底删除必须同时删除该rc
# 删除所有资源,包括rc, service等
kubectl delete all --all上述命令也会删除kubernetes的service,但这没有关系,因为几分钟后会自动重建。
k8s能够做到即使应用程序的进程没有崩溃,仅仅是应用停止响应,也能够重启应用程序。
存活探针检测容器是否还允许,有三种机制
- HTTP GET请求应用给出的IP地址,不返回数据或是返回错误状态码将会导致重启
- TCP套接字探针,与容器指定端口建立连接,建立失败则导致重启
- Exec探针,在容器内执行任意命令,执行结果的状态码非0则重启
......
spec:
containers:
- image: zou8944/kubia
name: kubia
# 指定路径为/,端口为8080的http探针
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15 # 在第一次探测前等待15秒,用于等待容器启动
......是一种k8s资源,可确保它的pod始终处于运行状态。没有RC管理的pod在终止后不会被重新创建。
RC对pod的跟踪,是使用标签选择器来进行的。
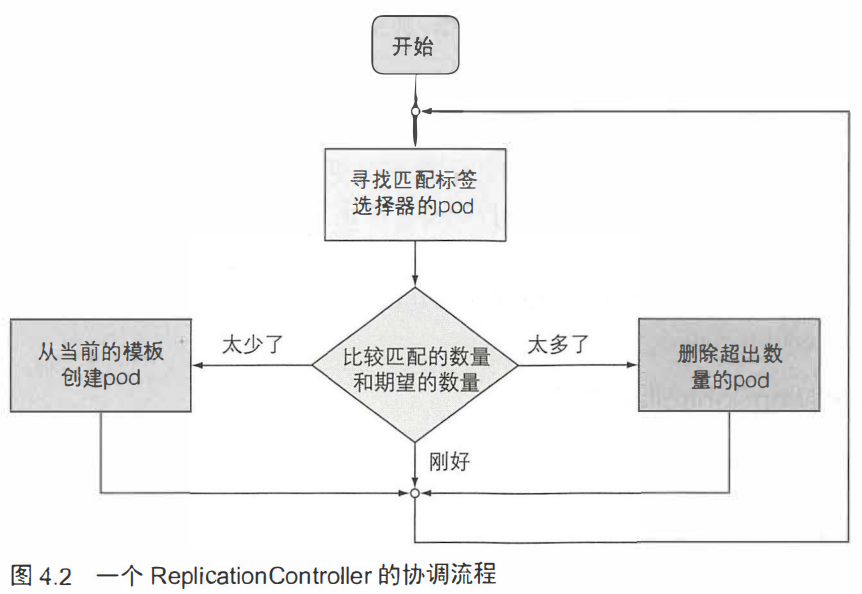
RC三个重要组成部分
- 标签选择器
- 副本个数
- pod模板:用于创建新的pod副本
pod和rc的联系仅在标签选择器,当该条件获取的结果不满足副本个数时,将会使用pod模板进行闯将。
使用yaml创建
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
# 确保的pod实例数量
replicas: 3
# selector决定了RC的操作对象
selector:
app: kubia
# 创建新pod时的模板
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: zou8944/kubia
ports:
- containerPort: 8080可以删除RC,但当通过kubectl delete删除时,对应的pod也会被删除。由于RC和POD只是管理与被管理的关系,因此可以做到只删RC而不删除POD
# 删除rc及其管理的POD
kubectl delete rc <rc name>
# 仅删除rc,不删除POD
kubectl delete rc <rc name> --cascade=falseReplicaSet是新一代的ReplicationController,并且最终会取代RC。所以实际使用中应该使用RS,而不是RC。上文中创建那么多RC只是为了学习演示。
行为上与RC完全相同,但是其标签选择器具有更强的表现力。
apiVersion: apps/v1beta2 # 版本必须是这个(不知道现在的版本还是不是)
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
matchLabels:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: zou8944/kubia......
spec:
replicas: 3
selector:
matchExpression:
- key: app
oprator: In # 支持的操作:In NotIn Exists DoesNotExist
values:
- kubia
......适用于需要在每个节点上都运行一个pod的情况,比如一些基础设施。最典型的例子就是kube-proxy进程
DaemonSet确保在符合条件的节点上运行一个指定的pod:新节点加入时主动创建一个pod,一个节点下线时不做任何操作
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels: # 匹配POD的节点
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector: # 该节点选择器用于匹配节点
disk: ssd
container:
- name: kubia
image: zou8944/kubia# 获取所有DaemonSet
kubectl get dsRC, RS, DS都会持续运行任务,永远达不到结束态。如果需要一种任务,完成工作后就马上结束,Job就很适用。
Job会在pod未成功执行完成而异常退出时重新启动一个pod,如果成功完成了则不再启动。
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job
spec:
completions: 5 # 将此容器顺序运行5个pod
parallelism: 2 # 最多两个pod可以并行运行
activeDeadlineSeconds: 30 # pod运行30秒还没有成功就中止并重试
restartPolicy: OnFauilre
containers:
- name: main
image: zou8944/batch-job# job运行时手动将并行运行个数改为3个
kubectl scale job batch-job --replicas 3在特定时间或特定间隔时间运行的Job
apiversion: batch/v1beta1
kind: CronJob
metadata:
name: periodic-batch-job
spec:
schedule: "0, 15, 30, 45, * * * * " # 每天的每小时的0,15,30,45分钟运行一次
startingDeadlineSeconds: 15 # pod最迟必须在预定时间的15秒内开始(可选)
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: zou8944/batch-job从左到右依次代表
- 分钟
- 小时
- 每月中的第几天
- 月
- 星期几 (0代表周天,以此类推)
CronJob会创建Job,Job再去创建pod。