| comments | difficulty | edit_url | tags | ||||
|---|---|---|---|---|---|---|---|
true |
Medium |
|
Each character of the English alphabet has been mapped to a digit as shown below.
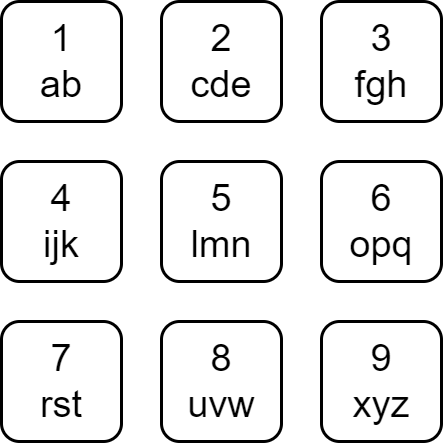
A string is divisible if the sum of the mapped values of its characters is divisible by its length.
Given a string s, return the number of divisible substrings of s.
A substring is a contiguous non-empty sequence of characters within a string.
Example 1:
| Substring | Mapped | Sum | Length | Divisible? |
|---|---|---|---|---|
| a | 1 | 1 | 1 | Yes |
| s | 7 | 7 | 1 | Yes |
| d | 2 | 2 | 1 | Yes |
| f | 3 | 3 | 1 | Yes |
| as | 1, 7 | 8 | 2 | Yes |
| sd | 7, 2 | 9 | 2 | No |
| df | 2, 3 | 5 | 2 | No |
| asd | 1, 7, 2 | 10 | 3 | No |
| sdf | 7, 2, 3 | 12 | 3 | Yes |
| asdf | 1, 7, 2, 3 | 13 | 4 | No |
Input: word = "asdf" Output: 6 Explanation: The table above contains the details about every substring of word, and we can see that 6 of them are divisible.
Example 2:
Input: word = "bdh" Output: 4 Explanation: The 4 divisible substrings are: "b", "d", "h", "bdh". It can be shown that there are no other substrings of word that are divisible.
Example 3:
Input: word = "abcd" Output: 6 Explanation: The 6 divisible substrings are: "a", "b", "c", "d", "ab", "cd". It can be shown that there are no other substrings of word that are divisible.
Constraints:
1 <= word.length <= 2000wordconsists only of lowercase English letters.
First, we use a hash table or array
Then, we enumerate the starting position
After the enumeration is over, return the answer.
The time complexity is
class Solution:
def countDivisibleSubstrings(self, word: str) -> int:
d = ["ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"]
mp = {}
for i, s in enumerate(d, 1):
for c in s:
mp[c] = i
ans = 0
n = len(word)
for i in range(n):
s = 0
for j in range(i, n):
s += mp[word[j]]
ans += s % (j - i + 1) == 0
return ansclass Solution {
public int countDivisibleSubstrings(String word) {
String[] d = {"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"};
int[] mp = new int[26];
for (int i = 0; i < d.length; ++i) {
for (char c : d[i].toCharArray()) {
mp[c - 'a'] = i + 1;
}
}
int ans = 0;
int n = word.length();
for (int i = 0; i < n; ++i) {
int s = 0;
for (int j = i; j < n; ++j) {
s += mp[word.charAt(j) - 'a'];
ans += s % (j - i + 1) == 0 ? 1 : 0;
}
}
return ans;
}
}class Solution {
public:
int countDivisibleSubstrings(string word) {
string d[9] = {"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"};
int mp[26]{};
for (int i = 0; i < 9; ++i) {
for (char& c : d[i]) {
mp[c - 'a'] = i + 1;
}
}
int ans = 0;
int n = word.size();
for (int i = 0; i < n; ++i) {
int s = 0;
for (int j = i; j < n; ++j) {
s += mp[word[j] - 'a'];
ans += s % (j - i + 1) == 0 ? 1 : 0;
}
}
return ans;
}
};func countDivisibleSubstrings(word string) (ans int) {
d := []string{"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"}
mp := [26]int{}
for i, s := range d {
for _, c := range s {
mp[c-'a'] = i + 1
}
}
n := len(word)
for i := 0; i < n; i++ {
s := 0
for j := i; j < n; j++ {
s += mp[word[j]-'a']
if s%(j-i+1) == 0 {
ans++
}
}
}
return
}function countDivisibleSubstrings(word: string): number {
const d: string[] = ['ab', 'cde', 'fgh', 'ijk', 'lmn', 'opq', 'rst', 'uvw', 'xyz'];
const mp: number[] = Array(26).fill(0);
for (let i = 0; i < d.length; ++i) {
for (const c of d[i]) {
mp[c.charCodeAt(0) - 'a'.charCodeAt(0)] = i + 1;
}
}
const n = word.length;
let ans = 0;
for (let i = 0; i < n; ++i) {
let s = 0;
for (let j = i; j < n; ++j) {
s += mp[word.charCodeAt(j) - 'a'.charCodeAt(0)];
if (s % (j - i + 1) === 0) {
++ans;
}
}
}
return ans;
}impl Solution {
pub fn count_divisible_substrings(word: String) -> i32 {
let d = vec!["ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"];
let mut mp = vec![0; 26];
for (i, s) in d.iter().enumerate() {
s.chars().for_each(|c| {
mp[(c as usize) - ('a' as usize)] = (i + 1) as i32;
});
}
let mut ans = 0;
let n = word.len();
for i in 0..n {
let mut s = 0;
for j in i..n {
s += mp[(word.as_bytes()[j] as usize) - ('a' as usize)];
ans += (s % ((j - i + 1) as i32) == 0) as i32;
}
}
ans
}
}Similar to Solution 1, we first use a hash table or array
If the sum of the numbers in an integer subarray can be divided by its length, then the average value of this subarray must be an integer. And because the number of each element in the subarray is in the range of
We can enumerate the average value
The time complexity is
class Solution:
def countDivisibleSubstrings(self, word: str) -> int:
d = ["ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"]
mp = {}
for i, s in enumerate(d, 1):
for c in s:
mp[c] = i
ans = 0
for i in range(1, 10):
cnt = defaultdict(int)
cnt[0] = 1
s = 0
for c in word:
s += mp[c] - i
ans += cnt[s]
cnt[s] += 1
return ansclass Solution {
public int countDivisibleSubstrings(String word) {
String[] d = {"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"};
int[] mp = new int[26];
for (int i = 0; i < d.length; ++i) {
for (char c : d[i].toCharArray()) {
mp[c - 'a'] = i + 1;
}
}
int ans = 0;
char[] cs = word.toCharArray();
for (int i = 1; i < 10; ++i) {
Map<Integer, Integer> cnt = new HashMap<>();
cnt.put(0, 1);
int s = 0;
for (char c : cs) {
s += mp[c - 'a'] - i;
ans += cnt.getOrDefault(s, 0);
cnt.merge(s, 1, Integer::sum);
}
}
return ans;
}
}class Solution {
public:
int countDivisibleSubstrings(string word) {
string d[9] = {"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"};
int mp[26]{};
for (int i = 0; i < 9; ++i) {
for (char& c : d[i]) {
mp[c - 'a'] = i + 1;
}
}
int ans = 0;
for (int i = 1; i < 10; ++i) {
unordered_map<int, int> cnt{{0, 1}};
int s = 0;
for (char& c : word) {
s += mp[c - 'a'] - i;
ans += cnt[s]++;
}
}
return ans;
}
};func countDivisibleSubstrings(word string) (ans int) {
d := []string{"ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"}
mp := [26]int{}
for i, s := range d {
for _, c := range s {
mp[c-'a'] = i + 1
}
}
for i := 0; i < 10; i++ {
cnt := map[int]int{0: 1}
s := 0
for _, c := range word {
s += mp[c-'a'] - i
ans += cnt[s]
cnt[s]++
}
}
return
}function countDivisibleSubstrings(word: string): number {
const d = ['ab', 'cde', 'fgh', 'ijk', 'lmn', 'opq', 'rst', 'uvw', 'xyz'];
const mp: number[] = Array(26).fill(0);
d.forEach((s, i) => {
for (const c of s) {
mp[c.charCodeAt(0) - 'a'.charCodeAt(0)] = i + 1;
}
});
let ans = 0;
for (let i = 0; i < 10; i++) {
const cnt: { [key: number]: number } = { 0: 1 };
let s = 0;
for (const c of word) {
s += mp[c.charCodeAt(0) - 'a'.charCodeAt(0)] - i;
ans += cnt[s] || 0;
cnt[s] = (cnt[s] || 0) + 1;
}
}
return ans;
}use std::collections::HashMap;
impl Solution {
pub fn count_divisible_substrings(word: String) -> i32 {
let d = vec!["ab", "cde", "fgh", "ijk", "lmn", "opq", "rst", "uvw", "xyz"];
let mut mp: Vec<usize> = vec![0; 26];
for (i, s) in d.iter().enumerate() {
for c in s.chars() {
mp[(c as usize) - ('a' as usize)] = i + 1;
}
}
let mut ans = 0;
for i in 0..10 {
let mut cnt: HashMap<i32, i32> = HashMap::new();
cnt.insert(0, 1);
let mut s = 0;
for c in word.chars() {
s += (mp[(c as usize) - ('a' as usize)] - i) as i32;
ans += cnt.get(&s).cloned().unwrap_or(0);
*cnt.entry(s).or_insert(0) += 1;
}
}
ans
}
}